Blog
October 5, 2023

With generative artificial intelligence (AI) dominating headlines around the world, it's no wonder that many teams are looking for ways to apply AI within their IT infrastructure. The good news is that AI isn't a new concept in the open source space. In fact, there are many open source technologies that are used in the creation of machine learning and AI applications.
In this blog, I'll walk through the current state of AI within the open source space, discuss bleeding edge open source AI tools available today, and the key open source machine learning technologies that are ready for enterprise use.
Back to topAI: The Latest Paradigm Shift in the Tech Ecosystem
Mainstream media largely paints advances in artificial intelligence (AI) as either Star Wars or Terminator. However, AI is nothing new. In fact, the first work considered AI by scientific historians are the artificial neurons from McCullouch and Pitts eighty years ago in 1943. Here at OpenLogic, depending on what lines you draw, we have been supporting machine learning (ML) tools since at least 2018.
That said, the recent advances in AI appear to be a paradigm shift much like shifts to virtualization or the cloud earlier this century. In fact, your company's posture toward cloud is likely a very good way to start to frame your company's policies around AI since AI tools can be run in the cloud like basically everything else.
Like virtualization and cloud before it, we do not leave the old tools behind us. There are a variety of items in your technology stack that are not going to change. AI tools are going to run on Linux servers. PyTorch uses the Python programming language and library ecosystem. Tensorflow also provides stable APIs in Python and C++, in addition to many compatible community APIs. With or without something specific to AI like Kubeflow, your AI workflows might be running on Kubernetes (K8s). Most any data engineering tool, such as Apache Cassandra, Apache Kafka, or Apache Spark, is going to be able to be leveraged in an AI pipeline.
Speaking of pipelines, tools like Jenkins are still there for you to build and deploy your AI code. In fact, INSAID has an eight-part series on an End-to-End AI stack where tons of open source is used. It starts back in 2021, and ends with a getting started guide of Jenkins which really proves the point that using Jenkins with your AI stack is really no different than using Jenkins in any other stack.
More importantly than the tools themselves, the high-level concepts are still there. While the current generation of tools require the same observability tools such as OpenTelemetry, Grafana, and Prometheus, the new tools will use something called XAI, or eXplainable AI. Much like observability, building, implementing, or purchasing a XAI tool is not going to solve all your AI problems. You must still be able to interpret the results your XAI tool is giving you. Depending on your toolset, that may be something with which OpenLogic can help!
Back to topThe Next Generation of Open Source Software Machine Learning Technologies
OpenAI, and large companies such as Microsoft, Google, and Meta have made headlines with their increased use of AI, but there are many open source tools available.
HuggingFace is one of the open source toolkits that is most akin to the consumer-facing generative AI tools that have made headlines. Although OpenLogic has not vetted HuggingFace for enterprise use, it is important to see where the open source ecosystem is headed.
One of HuggingChat’s stated goals is to "showcase that it is now (May 2023) possible to build an open source alternative to ChatGPT."
So, we asked it a question:
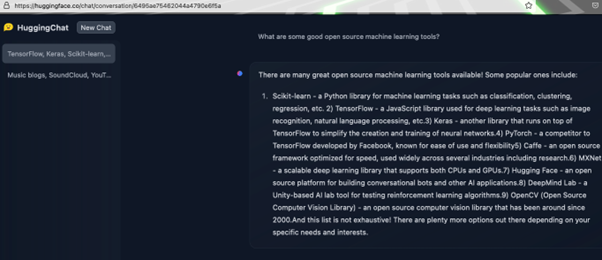
Let's pick this response apart one at a time:
- Scikit-learn is, in fact, a BSD 3-clause python library.
- Tensorflow was already discussed above, and is an application that OpenLogic supports. It is a little misleading to call Tensorflow a javascript library, though it is not exactly wrong. Tensorflow has a tfjs in its repo, which is self-describd as a WebGL accelerated JavaScript library for training and deploying ML models. One could forgiveHuggingFace for being confused since tfjs is more Typescript (80%) than javascript (9%).
- Keras – Checks out. Another library supported by OpenLogic.
- PyTorch – Checks out, but some important context left out earlier as to why the mention of Facebook (Meta) is important here. Tensorflow was developed first at Google (Alphabet).
- Caffe – An early player in this space, the last release was in 2017. We would highly recommend staying away unless you have the resources to patch C++ security vulnerabilities.
- MXNet seems to be an Apache project in a strange spot. It graduated from incubation in September 2022, but has not had a release since May 2022. This may be a project to look at in the future, but right now it seems there are other projects that may be healthier.
- HuggingFace – HuggingChat is part of HuggingFace. The proof here is in the pudding, as we humans like to say.
- DeepMind Lab – DeepMind has active repos on Github, but DeepMind Lab's last release was in 2020. Software that is not actively maintained, open source or not, is a huge security concern.
- OpenCV – Another project in the Python ecosystem.
Key Open Source Machine Learning Technologies
This lists many great AI-specific tools, but Apache Spark, with its Machine Learning libraries, is a notable omission. Thus, we asked HuggingChat for some additional projects. You can see the full conversation here.
In the second round, HuggingChat did mention Spark, as well as Apache Mahout. We do not currently support Mahout, though it is part of the Hadoop ecosystem, where we do offer support for select packages. The Mahout project notes “Apache Spark is the recommended out-of-the-box distributed back-end, or can be extended to other distributed backends.”
As noted above, many of the tools already in your technology stack are going to provide value in an AI stack. In reality, almost any open source tool could be part of an AI stack, but it is worth highlighting three that would seem to be of particular importance.
Apache Cassandra
Since Apache Cassandra can be used for a variety of different workloads, it makes sense that HuggingChat did not mention it. Still, Apache Cassandra is a product likely to feature in many enterprise AI stacks. It should be no surprise that Cassandra is built for AI workloads, having originally been built at Meta. Cassandra was designed to implement Amazon’s Dynamo distributed storage blended with Google’s Bigtable, so the lineage is strong.
Cassandra is built for large amounts of data, and is designed such that there is no single point of failure. This is perfect for machine learning workloads. Cassandra is highly tuneable, which means if you have workloads on historical data, you can optimize for reads, or if it is important that you have the latest data in your models, you can optimize for write performance.
The Cassandra ecosystem is going to be changing later this year, when 3.0 (released 2015) and 3.11 (released 2017) both go out of support with the release of Cassandra 5.0.
There is really no reason to be deploying Cassandra 3.x in 2023, but if you are currently on Cassandra 3.x, even aside from the EOL with Cassandra 5.0, there are are some pretty massive performance improvements. There are improvements across the board, but the improvement in write latencies is particularly impressive. There is additional information, including charts, at The New Stack.
Apache Kafka
Much like Apache Cassandra, Apache Kafka is not an AI-specific tool, but comes out of a company with huge amounts of data that needs to be moved at customer-facing speeds, namely LinkedIn. Cassandra is a true database, and while Kafka has some database qualities, as well as some properties of a messaging system (such as RabbitMQ), it is truly a distributed streaming platform. Not all AI stacks will need a streaming platform, but, increasingly, streaming platforms help enterprises reduce time to market.
Kafka’s place in the AI ecosystem seems cemented. TensorFlow has a Kafka tutorial. They also have tutorials for PostgreSQL, Elasticsearch, and MongoDB, as far as applications that we support here at OpenLogic. The ERTIS Reach Group at the University of Malaga has produced Kafka-ML, which works with both TensorFlow and PyTorch.
There’s a fun tutorial for using PyTorch and Kafka to voice control Tetris! Kafka in this scenario is used to pass the voice commands to the Kafka broker and then to consume the commands on the other side. While it is a straight-forward and fun way to learn Kafka, and machine learning, there are real-world enterprise use cases for Kafka in ML, such as content moderation systems.
Again, like Apache Cassandra, the Kafka community is in the middle of a monumental shift. Zookeeper is now gone and replaced by KRaft. The Kafka community moves fast. Luckily, OpenLogic offers Kafka LTS if you need more time on an end-of-life version.
Apache Spark
OpenLogic has supported Apache Spark since at least 2018, the project itself starting in 2014. We have three previous blogs on the subject if you want to dive deeper into the project:
- Processing Data Streams With Kafka and Spark
- Apache Spark Overview: Key Features, Use Cases, and Alternatives
- Apache Spark vs. Hadoop: Key Differences and Use Cases
Before diving into the Machine Learning libraries, called MLlib, it is important to note that Spark does more than ML. Spark SQL is for working with structured data. Spark Streaming is for streaming applications. GraphX is still in alpha stage, but is the Spark ecosystem’s answer for graph algorithms.
A quick glance at the MLlib guide will show terms that should stand out to anyone that has taken a cursory look at ML since the generative AI explosion; transforms, classification, clustering.
One of the easiest machine learning tools for beginners is linear regression. Spark has this! The documentation has examples for Scala, Java, Python, and R. Many of the classification and regression tools will work for all of those four languages, but R is not as flexible as the other languages. What R lacks in flexibility, it gains in specificity to the statistical use case. Still, what this means in practice is tools like one-vs-rest classifier (which the docs note is also known as one-vs-all) is not available in R.
You may be wondering why Spark does not have a Go library or why a high performance language like C++ is not involved. One way to use Go with Spark would be to use Apache Beam as a translation layer. The Apache Beam documentation gives this as an example:
# Build and run the Spark job server from Beam source.
# -PsparkMasterUrl is optional. If it is unset the job will be run inside an embedded Spark cluster.
$ ./gradlew :runners:spark:3:job-server:runShadow -PsparkMasterUrl=spark://localhost:7077
# In a separate terminal, run:
$ go run github.com/apache/beam/sdks/v2/go/examples/wordcount@latest --input <PATH_TO_INPUT_FILE> \
--output counts \
--runner spark \
--endpoint localhost:8099As for C++, it is possible through Scala. Additionally, Python allows calls to C/++. There does not appear to be any documented cases of using C/C++ with the new Spark Dataframe, but there are cases of this being done with the old RDDs.
Much like Zookeeper in Kafka, there is a period where RDDs will still be possible. While Cassandra and Kafka communities are undergoing monumental transitions, the Spark community has already done this with the move from the RDD API to the DataFrames API.
Spark is made to work with Tensorflow and PyTorch, which we already discussed, as many other tools we support such as Elasticsearch, MongoDB, Apache Airflow, and Kubernetes. (Note: You can search our full list of supported technologies here.)
Further, Cassandra, Kafka, and Spark are frequently used together, with Cassandra and Kafka both highlighted on the Spark homepage under “Storage and Infrastructure”.
You can read more about Cassandra, Kafka, and Spark in this whitepaper.
Back to topFinal Thoughts
While generative AI has produced many headlines, machine learning is simply the latest evolution in data analytics. OpenLogic is well placed to help you with the infrastructure underlying your data analytics as well as many facets of application development. As new AI/ML tools evolve in the OSS space, OpenLogic will be evaluating which tools are best for the enterprise.
Need Help With Cassandra, Kafka, or Spark?
OpenLogic provides expert, SLA-backed technical support for hundreds of open source technologies. Talk to an expert today to learn more about how we can support your entire open source infrastructure.