Blog
March 8, 2023

Kafka and Spark are two powerful, distributed computing frameworks that are often used together to process real-time data streams. While they have some similarities, they serve different purposes and have distinct features, and understanding their differences can help you choose the right tool for your specific use case.
In this blog, our expert explains how Kafka and Spark can work together to process data streams, the differences between Kafka vs. Spark (Kafka Streams and Spark Streaming), and steps to integrate the two technologies.
Back to topWhat Is Stream Processing?
Stream processing is a core concept of “Big Data” processing/analysis and event-driven architecture. In it simplest form, stream processing is reading an incoming stream of data, or sequence of events, in real time and performing some actions on that data producing an output.
These actions could range from a simple read of the data and placing into another data stream or data store, or something as complex as building fatter computational pipelines for CPU and GPU hardware. Regardless of whether we are talking about complex streams processing used in something like DMA (direct memory access) or something as simple as generating a sentiment score from product reviews on a website, at its core streams processing will look something like the diagram below.
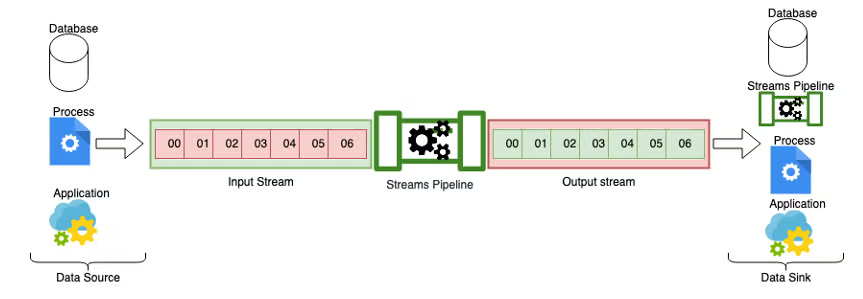
In other words, we are creating a streams pipeline from a data source (a database, process, application etc.), placing the data generated by the data source onto the streams pipeline, potentially doing some sort of work on the data, and outputting to a data sink. At some point in the pipeline, we may or may not be performing some enrichment on the data, such as doing some normalization or aggregation, and then outputting into to another database, application, or process. Or, in some cases we might be placing it into another streams pipeline, which in turn would become a data source for another pipeline.
How to Choose a Stream Processing Framework
For this blog post, we'll focus on user/application-generated data pipelines rather than stream processing utilized in computational models/architectures for things like GPUs and CPUs in hardware platforms. Excluding the obvious differences in those two styles of frameworks, when considering available steam processing frameworks for things like big data architectures, we obviously want to focus on the use case first. Does the framework we are selecting address the problems we are trying to solve? For instance, can the framework connect to our existing data sources and sinks easily? Does a native plugin or connector for our sources and sinks already exist in the framework, or would we have to write our own? Is that even possible within that framework, or do we have to use a third-party application to wire everything together?
Once it has been determined that the framework will be suitable for the given use case, the next thing to consider is, how widely is the framework adopted? What does the community base for the framework look like? Is there an active community for the framework that will allow us to draw from a large talent pool for development and operations? Is the project a closed or open source project?
Back to topKafka vs. Spark Overview
Apache Kafka and Apache Spark are both effective and powerful cogs in our big data architecture and our streams pipelines. While some of the functionality overlaps to a degree, Kafka and Spark sit in different, albeit adjacent, locations in that architecture.
The main difference between Kafka vs. Spark is that Kafka ingests and distributes messages and events, while Spark analyzes and processes data. Both technologies are capable of handling large batches of data in real time.
What Is Apache Kafka?
Kafka is an event streams processing system with a focus on high throughput and low latency delivery of data in real time.
Using a distributed network of brokers, producers place messages or records onto an append-only event log, which is then read by a consumer. Kafka partitions are how Kafka is able to scale, and processing millions of records with millisecond latency is achievable with this distributed model.
What Is Kafka Streams API?
Kafka Streams is tool used within the Kafka environment that enables Kafka to do more than just write and read records onto a Kafka topic.
While Kafka Connect helps us handle all the boilerplate code associated with producing and consuming messaging from something like MongoDB or a Redis cache, Kafka Streams helps reduce the amount of work required beyond just reading and writing the data.
For instance, if we had a Java consumer reading from a Kafka topic, we might only want that consumer to process messages with a specific identification number or unique key, say for a JSessionID generated from a visit to your web site, or a unique ID associated with click-stream events. The Kafka Streams API drastically reduces the amount of code we need to write to accomplish this by abstracting a lot of the consumer and producer logic and error handling that a built-from-scratch consumer/producer would need.
Related White Paper | The New Stack: Cassandra, Kafka, and Spark
What Is Apache Spark?
Apache Spark is powerful distributed data processing and analytics engine, meaning that it provides a wide range of integrated technologies to perform distributed data processing and analysis. It is a computational engine that provides a uniformed environment to handle structured SQL data, real-time streaming, graph processing, and machine learning.
Spark was designed around the concept of Resilient Distributed Datasets (RDD). RDD is a fault-tolerant dataset that allows for operations to be performed on the dataset in parallel, providing a working dataset for distributed applications to use as a limited form of shared memory.
What Is Spark Streaming?
Apache Spark Streaming is a distributed processing engine built on top of the Apache Spark framework. It enables real-time processing of data streams, allowing developers to analyze and manipulate data as it is being generated, rather than having to wait for the data to be stored in a database or file system.
Spark Streaming ingests data from various sources, such as Kafka, Flume, and HDFS, and divides it into small batches, which are then processed by Spark's parallel processing engine. The processed data can then be stored in various data stores or used for real-time analytics and visualization.
Spark Streaming supports a wide range of programming languages, including Scala, Java, Python, and R, making it accessible to a large community of developers. It also integrates with other Spark components, such as Spark SQL, MLlib, and GraphX, to provide a comprehensive data processing platform for both batch and real-time processing use cases.
Back to topSimplify Kafka's Complexity With the Kafka Service Bundle
Experience the benefits of managed, open source Kafka, customized for your infrastructure and monitored by experts 24/7.
Kafka and Spark Streaming
Apache Spark Streaming and Apache Kafka frameworks are often used together for real-time data processing. While they have some similarities, they serve different purposes and have distinct features.
Spark Streaming is built on top of the Spark framework. It enables real-time processing of data streams and provides a high-level API for developers to analyze and manipulate data as it is being generated. Spark Streaming divides data into small batches and processes them using Spark's parallel processing engine.
Kafka, on the other hand, is a distributed streaming platform that allows you to publish and subscribe to streams of data. Kafka is designed for high-throughput, low-latency processing of data streams and can handle real-time data ingestion and processing. Kafka provides durable storage and replay-ability of data streams, which makes it suitable for building reliable and scalable data pipelines.
Some key differences between Kafka and Spark Streaming:
- Processing model: Spark Streaming provides a high-level API for processing data streams using Spark's parallel processing engine, while Kafka provides a distributed messaging system for handling real-time data streams.
- Data storage: Spark Streaming stores data in memory or disk, depending on the configuration, while Kafka stores data in distributed, fault-tolerant, and scalable log files called topics.
- APIs: Spark Streaming provides APIs for several programming languages, including Scala, Java, Python, and R. Kafka provides APIs in several programming languages, including Java, Scala, Python, and .NET.
- Use cases: Spark Streaming is suitable for data processing use cases that involve complex analytics, machine learning, and graph processing. Kafka is suitable for real-time data streaming use cases, such as clickstream analysis, fraud detection, and real-time analytics.
Kafka and Spark Integration Steps
Integrating Kafka and Spark can help you build a reliable and scalable data processing pipeline that can handle real-time data streams and turn them actionable Complex Event Processes (CEPs). Here are some steps you can take from an enterprise architecture perspective to integrate these two frameworks:
- Identify the use case: Identify the specific use case for integrating Apache Spark and Apache Kafka. This will help you define the requirements and design the architecture.
- Define the data flow: Define the data flow from the data source to the final destination. This includes identifying the data sources, the transformation required, and the final destination.
- Choose the right deployment architecture: Choose the deployment architecture that suits your requirements. This includes identifying the number of Kafka brokers, Spark nodes, and other components required for your specific use case.
- Configure Apache Kafka: Configure Apache Kafka to suit your requirements. This includes configuring topics, partitions, replication, and security.
- Configure Apache Spark: Configure Apache Spark to suit your requirements. This includes configuring the Spark Streaming context, the data sources, and the processing logic.
- Implement the data processing pipeline: Implement the data processing pipeline using Apache Kafka and Apache Spark. This includes ingesting data from Kafka topics, processing data using Spark Streaming, and storing the processed data in the final destination.
- Test and optimize the pipeline: Test and optimize the data processing pipeline to ensure that it meets the performance and scalability requirements. This includes load testing, tuning, and monitoring.
- Deploy and maintain: Deploy the integrated solution in your production environment and ensure that it is maintained and updated as required.
In summary, integrating Kafka and Spark requires careful planning and architecture design. However, by following these steps, you can build a reliable and scalable data processing pipeline that can handle serious real-time data streams.
Back to topFinal Thoughts
Many enterprise teams rely on Spark and/or Kafka for stream processing use cases. Understanding exactly how each technology works and how they differ is essential to implementing them effectively and finding long-term success.
Get SLA-Backed Technical Support for Kafka and Spark
Need to speak with a data processing expert? Learn more about how you can leverage Apache Kafka and Apache Spark by connecting with an OpenLogic Enterprise Architect.
Additional Resources
- Blog - Solving Complex Kafka Issues: Enterprise Use Cases
- Whitepaper - The Decision Maker's Guide to Apache Kafka
- Video - Apache Kafka Best Practices
- Blog - Using Cassandra, Kafka, and Spark for AI/ML
- Blog - Spark vs. Hadoop
- Blog - 8 Kafka Security Best Practices
- Guide - Enterprise Kafka Resources
- Webinar - Real-Time Data Lakes: Kafka Streaming With Spark
- Blog - When to Choose Kafka vs. Hadoop