Blog
January 10, 2019

As part of DevOps, many companies today are migrating to microservices architecture with Kubernetes and other open source technologies. In this blog, we share the benefits of Kubernetes for microservices architecture and give you tips on how to transition.
Back to topWhy Use Kubernetes For Microservices Architecture?
Using Kubernetes can help you innovate faster. Teams using Kubernetes achieve higher productivity. But you can't have a monolithic application in Kubernetes.
Kubernetes is, however, a great platform for microservices architecture. Using Kubernetes containers makes it easier to build a microservices architecture. And there are many benefits to a microservices architecture with Kubernetes.
Back to topBenefits of Using Kubernetes For Microservices Architecture
The top benefits of using Kubernetes for microservices architecture are:
- Faster development and deployment: teams using Kubernetes for microservices architecture can move faster.
- Ease of use: Kubernetes makes it easy to build microservices applications.
- Flexibility: Each microservice can be written using different technology, helping cross-functional teams work better.
Back to topKubernetes Is Just One Part of Your Stack
Your microservices architecture is built on other open source technologies, too. By partnering with a full stack vendor like OpenLogic, you can consolidate your OSS support. We support more than 400 open source packages; click the button below to explore.
How to Transition to Microservices Architecture With Kubernetes
Here's how to transition to microservices architecture using Kubernetes.
1. Review Your Existing Architecture
Before you tear down your existing architecture, you need to understand it.
Here's an example based on when I worked with a team rearchitecting for Kubernetes.
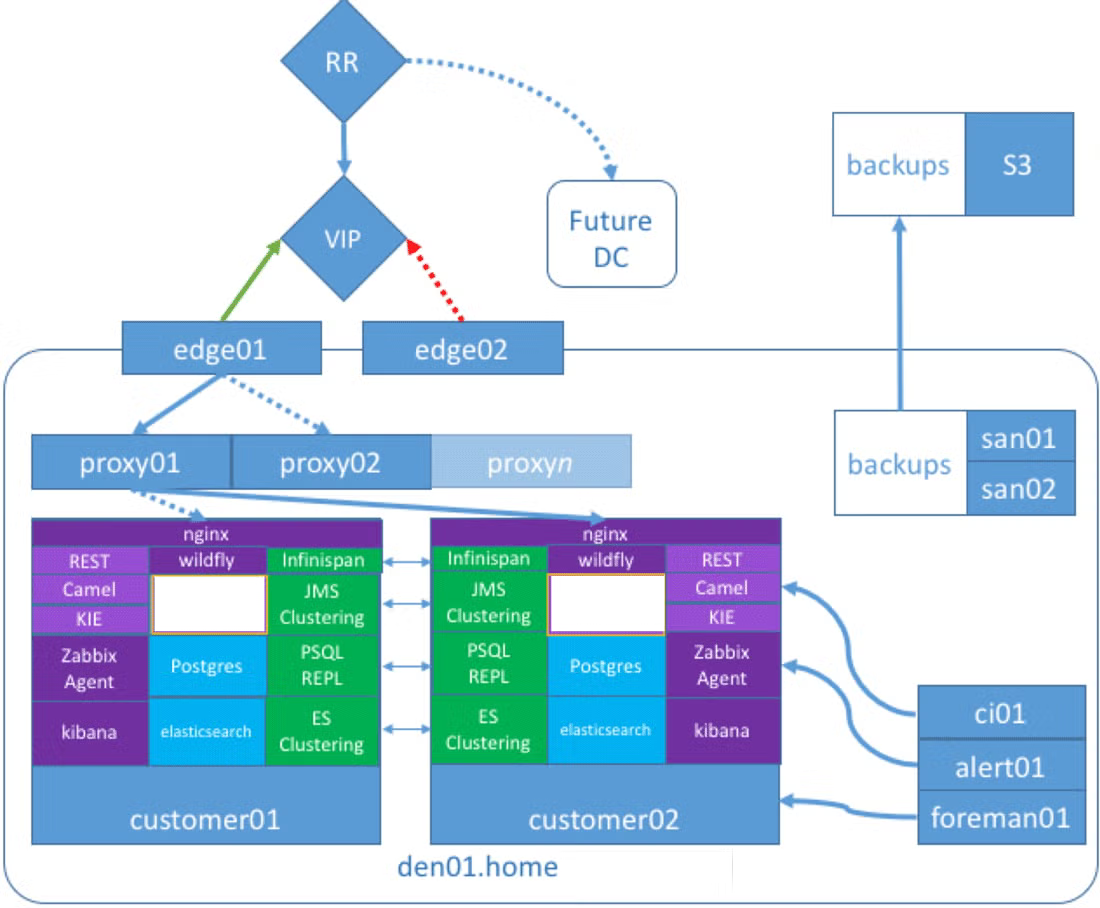
This complex architecture represents a line of business (LOB) software developed for a highly regulated industry that needed to meet pharmaceutical-grade chain-of-custody requirements in the United States.
By documenting the architecture, you can understand what's working and what's not working. This includes the current technologies you're using.
2. Assess the Current Technologies
You also need to assess your current technologies.
Here's what this example LOB application used:
- Camel and SwitchYard were used to develop a message-driven app integrated into KIE Drools and jBPM for human task orchestration.
- Zabbix was used to monitor the system.
- Kibana was used to report on the eventually consistent data journaled to Elasticsearch, while the ACID-transacted “live” state of the system was persisted to PostgreSQL.
- WildFly, the open source version of JBoss, hosted all of the Java applications.
All of these services were highly available, and most were available as Active/Active services. Camel and SwitchYard were stateless, KIE jBPM was configured with ZooKeeper for replication of the GIT filesystem, and Infinispan was used to cluster the session information. PostgreSQL was managed by PGpool-II, and the native Elasticsearch clustering was utilized for Elasticsearch.
3. Evaluate Resource Usage
You also need to evaluate your resource usage.
The LOBAPP deployment in WildFly was collocated with the KIE jBPM Workbench deployment. So, the high availability was performed in a Hot Active/Passive manner. This guarantees uptime, but doesn't reap any of the rewards of running an n-tier, or even load balanced, system.
To avoid bottlenecks, customers were given two VMs per deployment. This further impacted resources and costs for the LOBAPP, which was sold as a SaaS. This hurt the company that was developing the software, as stakeholders questioned the ability to scale the model.
Nginx was used to create path-based load-balancers internal to the services on the VM. Puppet and Foreman would deploy this incredibly complex VM. The system ran well and didn’t require a lot of intervention. It was clean and easy to troubleshoot.
However, the biggest problem was resource utilization and time-to-live for new customers.
Sales people had to wait up to an hour for a new instance to finish provisioning. Teams would prep a day in advance of a meeting just to make sure the environment was ready for a demo, eating up even more resources on the private cloud. This SaaS offering was eating too much of its margin on this expensive per-customer deployment.
The decision to migrate to a multi-tenant microservice mesh would greatly improve the scalability of this system. Additionally, this wouldn’t require a major rewrite, especially because of the message-driven nature of the application.
4. Decide What the Microservices Architecture Should Look Like
Let’s walk step by step through the architectural decisions that were made when migrating the application from a VM monolith to a Kubernetes multi-tenant microservice.
Early on in the architecture process, we decided that because of the messaging-driven nature of the application, the microservices architecture should look exactly like one of the VMs, but exploded:
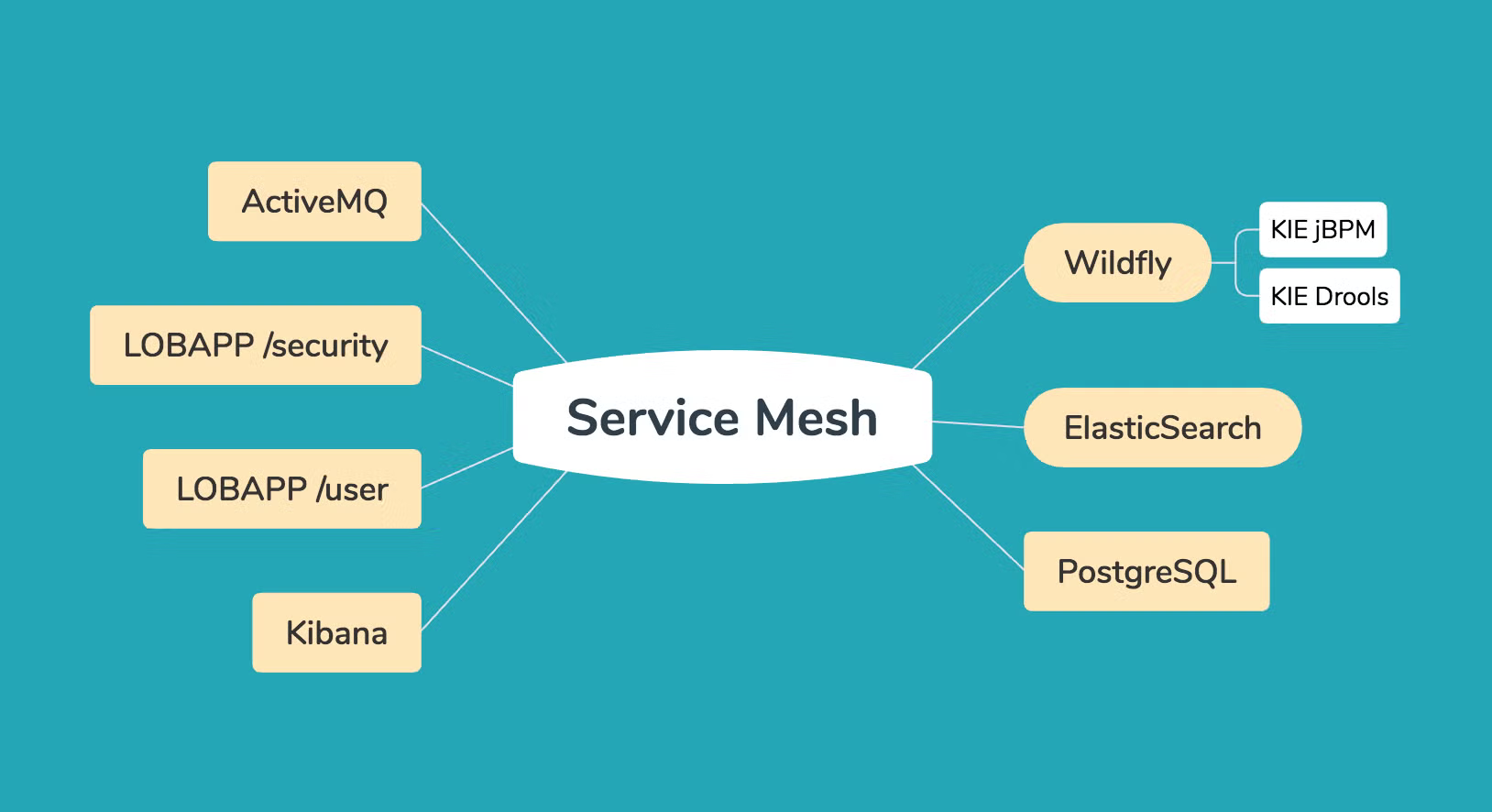
The WAR deployment methodology should be similarly exploded, breaking the services apart by domain, and interconnecting them by adding a message broker like ActiveMQ. Calls to HTTPS endpoints would be handled by a service mesh, like Istio.
How could we say that with confidence, though?
Architecturally, we understood two things as absolutes:
- All external “client” requests were being made over HTTPS (the global DDOS prevention service and datacenter load balancer had two rules: 80, and 443).
- There was a service endpoint connected to JMS for each action on the LOB APIs.
5. Determine How Communication Will Work
Next, you'll need to determine how communication will work in your microservices architecture with Kubernetes.
To do this, you should be able to enumerate the services on your current architecture externally and “internally.”
Externally is easier because you can ask the firewall team, but internally is a bit more difficult. How does Module A in your service communicate with Module B? If it’s not using HTTPS, is it using a portable protocol that’s going to be compatible with your service mesh? Can it be encapsulated in HTTPS, perhaps over websocket?
6. Consider Security
Finally, you'll need to consider security.
Because the application had already implemented JWT and SSO correctly (through Keycloak), implementing multi-tenancy wasn’t an issue as far as authentication was concerned.
All of the customers already came through url.tld/app/customerinstance to be routed to their VM. A soft-multitenancy model could continue to be supported in this way. The global VIP outside of the private datacenters could load balance traffic to a geographically appropriate DC or a hot-spare DC.
That’s where this exercise can get exciting, because in the case of this application, the monolith deconstructs pretty gracefully. But what if the “WildFly / KIE jBPM / Drools” aspect wasn’t something that could be containerized or even virtualized? What if it was an AS/400 mainframe?
This is where the abstraction layers in Camel can get exciting for your team: extract as much as possible away from the monolith, so that you can n-tier and elasticize the workload.
Back to topGet Help Transitioning to Microservices Architecture and Kubernetes
Transitioning to microservices architecture and adopting Kubernetes can be challenging. Unless you enlist the help of the experts.
OpenLogic experts are skilled in all things microservices and Kubernetes. We can help you:
- Evaluate your current architecture.
- Plan your transition to microservices architecture.
- Move your workloads to Kubernetes.
- Get support for all of the open source technologies involved.
Talk to an OpenLogic expert today to learn how we can help you get the speed, flexibility, and ease-of-use of Kubernetes and microservices architecture.
Back to top