Blog
April 24, 2026
Top Open Source Databases and Data Technologies in 2026

Databases,
Apache Kafka
Open source databases are a foundational component of modern application and data architectures. According to the 2026 State of Open Source Report, fewer than 5% of organizations report not using any open source databases or data technologies — highlighting how deeply embedded these tools are across industries and workloads.
This article examines database adoption patterns, Big Data trends, data hosting strategies and challenges, and Apache Kafka usage insights taken from the 2026 State of Open Source Report. All statistics referenced below are based directly on survey responses from open source users.
Back to topOpen Source Database Adoption in 2026
Open source database adoption remains high across organizations of all sizes, with usage concentrated around a small group of well‑established technologies.
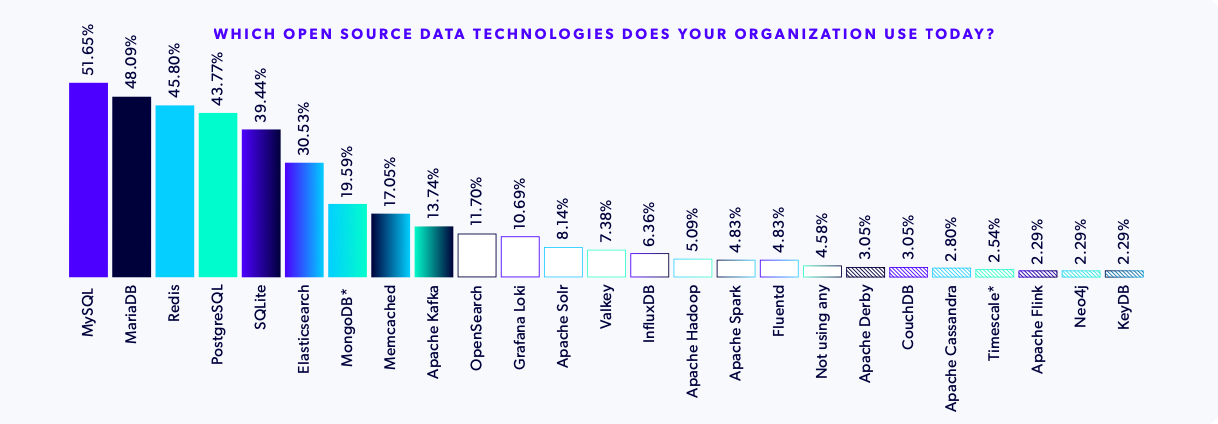
MySQL, MariaDB, Redis, and PostgreSQL Are the Most Popular Open Source Databases
The most widely used open source databases in 2026 are MySQL, MariaDB, Redis, and PostgreSQL. This is the first year we've seen Redis crack the top 3, which is interesting given recent licensing drama which prompted some to switch to Redis alternatives and forks like Valkey.
MySQL reclaimed the top position this year, with 51.65% of organizations reporting using it. MariaDB follows closely at 48.09%, with Redis and PostgreSQL just a few percentage points behind, used by 45.80% and 43.77% respectively. These close adoption margins reflect continued confidence in mature relational databases as the backbone of application data layers.
For teams evaluating or maintaining relational platforms, OpenLogic’s Guide to Open Source Relational Databases provides a deeper comparison of MySQL, MariaDB, PostgreSQL, and other enterprise‑ready options.
Most Organizations Use Multiple Open Source Databases
Rather than standardizing on a single database, most organizations intentionally deploy multiple open source data technologies. In 2026, 81% of respondents report using more than one open source database or data technology.
The most common combinations pair relational databases — such as MySQL, MariaDB, PostgreSQL, and SQLite — with caching or search technologies like Redis and Elasticsearch. This pattern suggests organizations are optimizing for specific workloads, performance requirements, and architectural needs rather than forcing all use cases into one platform.
Postgres Adoption Higher in Enterprise and Big Data Environments
While PostgreSQL ranks fourth overall, its adoption is significantly higher in more demanding environments. PostgreSQL usage climbs to 52.50% among large enterprises and 47.06% among organizations working with Big Data.
This is likely due to its extensibility: Postgres can be used as time-series database or a message queue, as well as for configuration management (via Dapr or AWX), geospatial data, NoSQL-like document storage, and vector embeddings (which power machine learning).
Back to topHow Confident Are Organizations About Their Big Data Management?
Nearly 30.51% of survey respondents said that they manage, process, or analyze large datasets. Confidence in managing Big Data stacks, however, varies depending on the technologies in use, as we'll explore in a moment. Across all Big Data users, the average confidence score for managing Big Data technologies is 3.4 out of 5, indicating moderate confidence.
Open Source Big Data Users Report Higher Confidence
Organizations relying on open source Big Data tools are slightly more confident about the management and administration of their tools (3.5) than those using proprietary platforms (3.2). This suggests that tool transparency, flexibility, and access to a broader talent pool may positively influence operational confidence.

For organizations weighing open source versus proprietary data platforms, Taking an Open Source Approach to Big Data Management explains why making the move to OSS can result in significant savings as well as greater digital autonomy and data portability.
Big Data Confidence Varies by Industry, Region, and Size
Confidence in Big Data management also varies across organizational contexts:
- Education and research organizations report the highest confidence levels
- Finance and healthcare, both highly regulated industries rank among the least confident
- Asia shows higher confidence than Europe, which has the strictest standards around data privacy and residency
- Mid‑sized enterprises (500–5,000 employees) report lower confidence than both small startups and very large organizations
These differences highlight how regulatory pressure, resourcing models, and operational complexity can shape Big Data outcomes.
Back to topBig Data Hosting Preferences and Priorities in 2026
Big Data workloads are distributed across environments rather than concentrated in a single model:
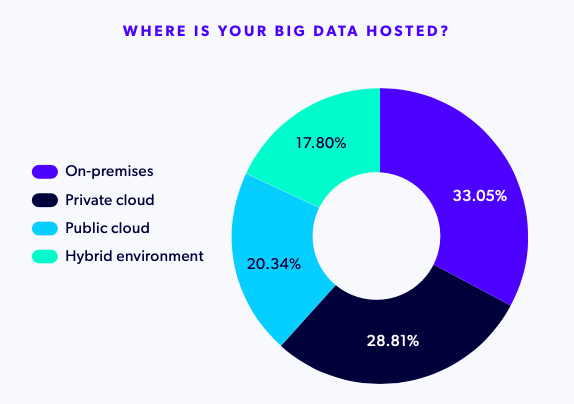
Hosting preferences vary notably by region:
- Europe shows the strongest preference for on‑prem Big Data deployments
- Asia favors public cloud environments
- North America is more evenly distributed, with higher private cloud and hybrid adoption
Data residency regulations, privacy requirements, and emerging compliance frameworks are likely influencing these regional choices.
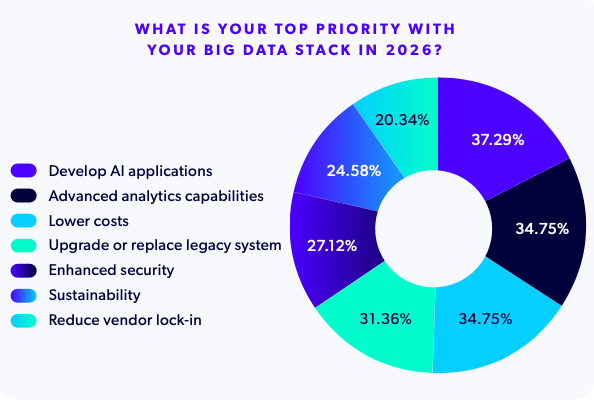
In terms of priorities, it's no surprise that developing AI applications is #1, as LLMs need vast amounts of data for training purposes, followed by powering advanced analytics and lowering costs (tied for second place):
Apache Kafka Usage and Upgrade Patterns in 2026
Apache Kafka remains an important component of open source data stacks, particularly for streaming and event‑driven architectures.
Kafka Adoption Is Even Across Organization Sizes
While we saw a clear correlation between organization size and PostgreSQL adoption, 48% of Kafka users work for companies with more than 500 employees and 52% for companies with fewer than 500 — a pretty even split.
Kafka version adoption reveals a strong preference for stability:
- 60% of users are still running Kafka 3.8 or 3.9, both reaching community end‑of‑life in 2026
- 26% have migrated to Kafka 4.0, the latest major version
- Only 18% of large enterprises are deploying Kafka 4.0 or higher
Kafka releases three versions a year and we asked how often organizations upgrade Kafka — 31% said they only upgrade Kafka when critical security patches or fixes are required, while others do it every one to three years. This indicates most teams prioritize operational stability over rapid adoption of new features.
Solutions
Expert Kafka Support and LTS
OpenLogic provides SLA-backed technical support, LTS, and professional services including upgrades, training, and implementations for Apache Kafka.
Key Challenges Managing Open Source Databases and Data Platforms
Despite widespread adoption, managing open source data technologies remains challenging. The most common issues organizations report include:
- A lack of skilled personnel
- Difficulty upgrading to supported versions
- Keeping up with updates and security patches
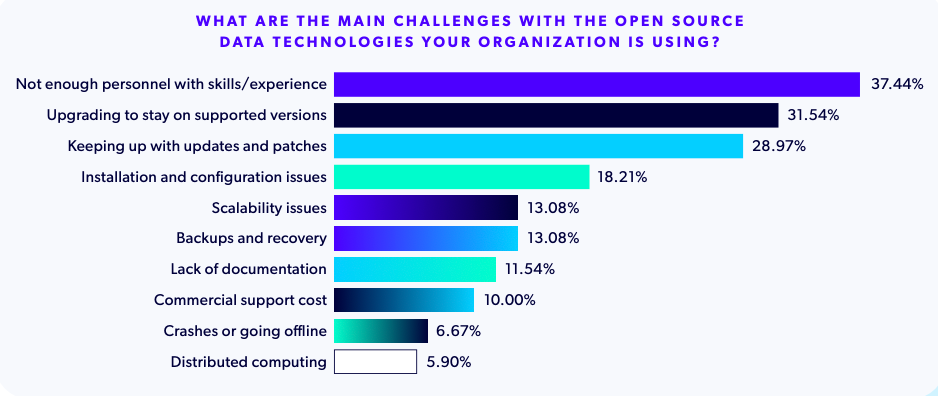
For Big Data stacks specifically, challenges such as data integration, scalability, real‑time processing, governance, and cost predictability remain significant — particularly for organizations relying on proprietary platforms.
Back to topWhat the 2026 Data Signals for Open Source Database Strategies
Open source databases are ubiquitous, but operational maturity is a key factor in determining long-term success.
Most organizations now rely on polyglot data stacks, combining multiple open source databases and data technologies to support diverse workloads. Open source users generally report higher confidence managing Big Data than those using proprietary tools, but some teams may lack the internal expertise to maintain and support technologies like Hadoop, Spark, and Kafka.
As database and Big Data environments grow more complex, the ability to maintain, upgrade, and govern open source systems effectively is becoming just as important as choosing the right software. Partners like OpenLogic play a critical role by offering unbiased guidance, technical support, and bundled services for organizations that want to avoid commercial tool lock-in by deploying OSS.
Report
Want More Insights? Read the Full Report
Get your free copy of the State of Open Source Report for more analysis on open source frameworks, Enterprise Linux distributions, infrastructure technologies and more!
Additional Resources
- Blog - Key Insights from the State of Open Source Report
- Solution - Open Source Database Support and Services
- Webinar - The State of Open Source in 2026
- Blog - (Re)Assessing Your Big Data Strategy
- Guide - Using Hadoop for Big Data
- Blog - Pros and Cons of Open Source Databases
- Guide - Intro to Open Source Databases
- Course - MySQL and PostgreSQL Training
- Blog - Guide to Key-Value Databases