Blog
November 7, 2022

Kafka on Kubernetes is a powerful combination deployed by more and more enterprise IT teams as cloud-native development and microservices have become increasingly popular. When combined with Strimzi, managing and running Kafka on Kubernetes is easy — whether that's on-prem, or across public, private, or hybrid clouds.
In this blog, we will explain why it makes sense to install Apache Kafka on Kubernetes, what Strimzi does, and how to quickly spin up a Kafka cluster in a Minikube environment.
Back to topWhy Run Kafka on Kubernetes?
The rise of Apache Kafka as a stream processing platform has coincided with the movement toward event-driven architectures (EDAs) and containerization, and running Kafka on Kubernetes allows it to be deployed in the most native way possible. Because of its architecture, Kafka on Kubernetes works particularly well, and for organizations that are already using Kubernetes for container-based applications, Kafka (with Strimzi) simplifies many operations at scale.
Back to topVideo: Kafka & Making the Move to Kubernetes
Kafka Architecture and Supporting Components
Before diving into how to deploy Kafka on Kubernetes, let's briefly review the main components of Kafka. In Kafka, records are stored in topics, and topics get divided into partitions. Kafka partitions create multiple logs from a single topic log and spread them across one or more brokers to handle message delivery.
To coordinate the flow of data between consumers, producers, and brokers, Kafka leverages ZooKeeper. Kafka and ZooKeeper work together to form a Kafka cluster, with ZooKeeper providing distributed clustering services, storing all kinds of data configurations, and coordinating the cluster itself, both brokers and consumers.
Other supporting components:
- Kafka Connect, which imports and exports streaming data through source or sink connectors
- Kafka MirrorMaker, which allows the user to replicate data between Kafka clusters
- Kafka Exporter, which extracts information for analysis and monitoring purposes, such as Prometheus metrics
- Kafka Bridge, which provides an API to obtain HTTP-based requests to the Kafka cluster
Here’s a diagram showing how these components are integrated:
Source: Strimzi
Back to top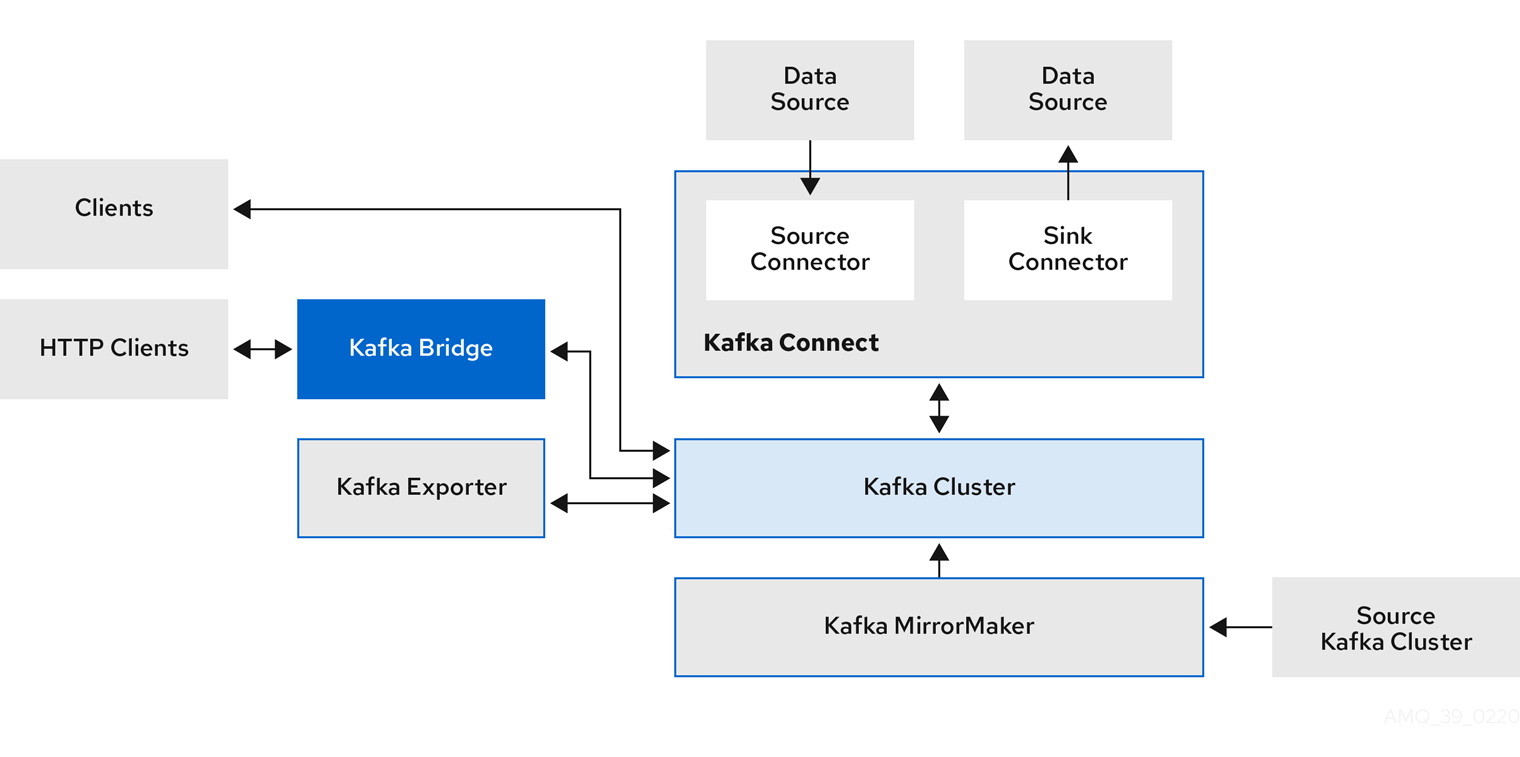{kind=link}
What Is Strimzi?
Strimzi is a CNCF-incubated project that simplifies the process of installing and running Kafka on Kubernetes. Strimzi provides different operators that allow you to deploy and manage Kafka clusters on Kubernetes in a declarative way. The operators speak with custom resources and YAML, allowing a Kubernetes application to be packaged, deployed, and managed.
How Does Strimzi Work?
Strimzi extends the functionality of Kubernetes through its operators, simplifying any process where manual intervention was previously required. Strimzi also enables the management of components such as Kafka Connect, MirrorMaker, or users and topics, extending its declarative capabilities.
Strimzi currently provides the following operators:
- Cluster Operator – Allows deployment of any type of Kafka and Zookeeper clusters, as well as Kafka Connect, Kafka MirrorMaker, Kafka Bridge, Kafka Exporter and the Entity Operator
- Entity Operator – Includes the Topic Operator and User Operator
- Topic Operator – Manages Kafka topics
- User Operator – Manages Kafka users
As previously mentioned, Strimzi makes use of custom resources, which are created as API instances that are added by Custom Resource Definitions (CRDs) to Kubernetes. This makes it possible to create any CRD and objects within a cluster, and when used, it is available as if it were a native Kubernetes object.
Whitepaper
Download Our Free Kafka Guide for More Expert Tips
The Decision Maker's Guide to Apache Kafka can help you configure, improve, and maintain your entire Kafka stack, and includes the most up-to-date information on deploying Kafka with or without ZooKeeper, security and configuration best practices, Kafka alternatives and more!
Creating a Kafka Cluster on Kubernetes With Strimzi
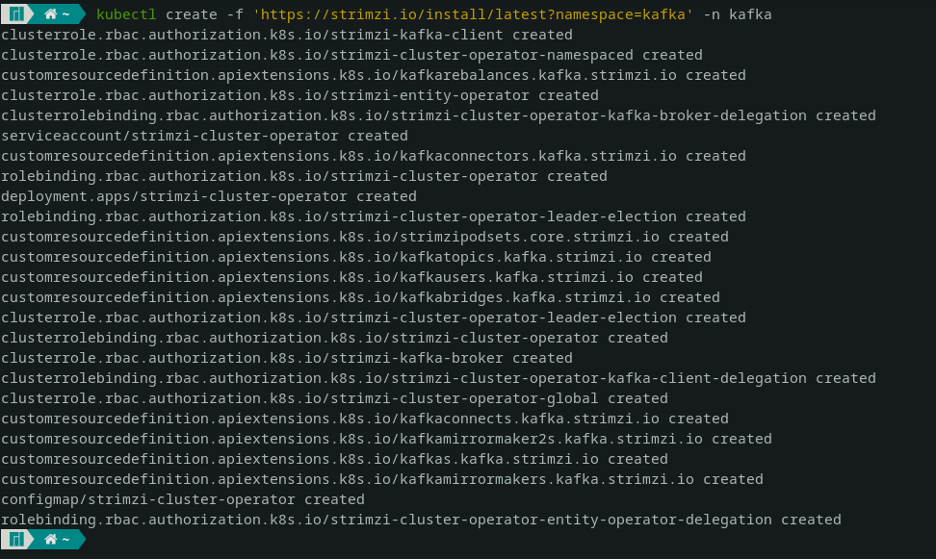
First, create a namespace named “kafka”:

The most common method to install a Kafka cluster with Strimzi is the following:
Now we have created a Kafka cluster that in turn deployed an operator pod. Let's visualize it:

And this pod, in turn, extends the capabilities of Kubernetes through CRDs with new Kafka objects.
In order to create a Kafka cluster, we need to create a Strizmi Kafka Resource. To do this, we are going to describe a yaml file named kafka.yaml:
In this example, the storage type is ephemeral, so that the duration of the data is linked to the lifetime of the Kafka broker Pod through the emptyDir volume. This includes 3 replicas of Kafka brokers and 3 of Zookeeper.
To create the cluster, simply apply the kafka.yaml configuration:
Now we are ready to produce and consume messages:

On another terminal, we can execute the default consumer inside the pod to get the messages:

So now we have successfully installed the Strimzi operator, deployed a first resource for a Kafka cluster, and tested it by producing and consuming some messages.
Back to topFinal Thoughts
80% of the Fortune 100 rely on Apache Kafka and for good reason — it is exceptionally durable and can handle massive amounts of streaming data. On Kubernetes, Kafka truly shines; DevOps teams can easily scale and manage all their Kafka instances in a single environment. Strimzi is particularly useful when running Kafka on Kubernetes because its operators automate much of the work that would otherwise have to be done at the infrastructure level.
We outlined one deployment configuration for Kafka on Kubernetes with Strimzi in a Minikube development environment above; stay tuned for future posts where we’ll look at some other exciting use cases involving these technologies.
Additional Resources
- Explore Solutions - Kafka Service Bundle, Kafka LTS, and Technical Support
- On-Demand Webinar - Kafka on K8s: Lessons From the Field
- Guide - Enterprise Kafka Resources
- Blog - Top 3 Reasons to Choose Kubernetes for Microservices
- Blog - OpenShift vs. Kubernetes
- Blog - Kubernetes Orchestration Overview
- Blog - Kafka Streams vs. Flink